#
Rules Configuration
Rules are the most crucial part of any Tilores installation. They define how records are connected into entities and also how you can search trough your existing entities.
Ideally, you already have an idea of how you want to match your records. If not we strongly advise you to understand the concept of matching and also of deduplication and get an idea of what is possible using Tilores. Afterwards you should spend a good amount of time to figure out the rules that match your needs.
#
The Basics
Before we can start with the actual configuration, we have to reach a common understanding about the wording.
#
Linking
We talk about linking, when we compare two records with each other with the purpose of identifying whether these two records belong to the same entity or not. The result from this comparison is that these records either match or not match - there is no uncertainty (you may be able to define thresholds though). The linking happens during the so called assembly process, that is the process that runs after records have been submitted into your Tilores instance and need to be assigned to an entity.
The linking can happen either between two records that have been submitted together or between one record that has been submitted and another record that is already stored in Tilores.
Within the assembly process there are different parts in which linking may happen. When a list of records is submitted, then each record from that list is compared with all other records from the same list. Afterwards each record from that list is compared with all records already stored in Tilores. If there is at least one match from the second comparison then the records will be attached to that entity (or multiple entities will be merged).
#
Edges
You can think of Tilores as a huge undirected graph, where each record represents one node in that graph. Each pair of records that match can be represented as an edge in that graph. Each connected component of that graph then represents an entity.
An edge in Tilores is represented in the following form:
<record-id>:<other-record-id>:<label>for example:
6373d7c6-c6bb-4a6f-8275-1dcc12b2f4a7:e4e30d6e-31d2-4b4f-b472-73e5b52c6250:R1EXACTThere are two kinds of edges - static edges and rule based edges.
Static edges are created between all records that were submitted together. E.g.
submitting the records 1, 2 and 3 together will create the following
edges:
1:2:STATIC
1:3:STATIC
2:3:STATICRule based edges on the other side are created whenever a match between two records is found. Also it is possible to have multiple edges between the same records when there are multiple satisfied rules.
E.g. using the previous records, it would be possible to have links between
1 and 2 and also between 2 and an already stored record 4.
The resulting edges could be:
1:2:STATIC
1:3:STATIC
2:3:STATIC
1:3:R1EXACT
2:4:R1EXACT
2:4:R2EXACTFor an easier understanding we will use the following visual representation instead of the textual one.
graph LR subgraph A 1---|STATIC|2 1---|STATIC|3 2---|R1EXACT|4 2---|R2EXACT|4 2---|STATIC|3 1---|R1EXACT|3 end classDef node stroke-width:2px,fill:#fff,stroke:#F6A77F classDef cluster fill:#7FCEF6,stroke:#7FCEF6 classDef edgeLabel background-color:#7FCEF6 classDef label fill:none
#
Searching
We talk about searching when we compare the input search parameters with all other records that have been already submitted into Tilores. It is comparable with the matching, with the exception that the search parameters may have a different structure than the records.
Where the result of matching are edges, the result of searching are hits. They serve a similar purpose, but are structured slightly different for easier use:
{
"2": ["R1EXACT", "R2EXACT"],
"3": ["R1EXACT"]
}In this example, the search found the records 2 and 3 and lists the rules
that were satisfied.
#
Indexing
Indexing means to make parts of an record available for searching and matching. Generally speaking, every rule that you want to use for either of these two, must also be added to the index. Otherwise it will not yield any results.
Most of the time you will not need to worry about indexing. The Tilores UI will take care of adding the rules to the index configuration.
#
Rules and Rule Sets
Tilores is based around the concept of rules and rule sets.
Each rule is build from one or more matchers. For a rule to be
satisfied, all of its matchers must be satisfied. Technically speaking they are
AND connected.

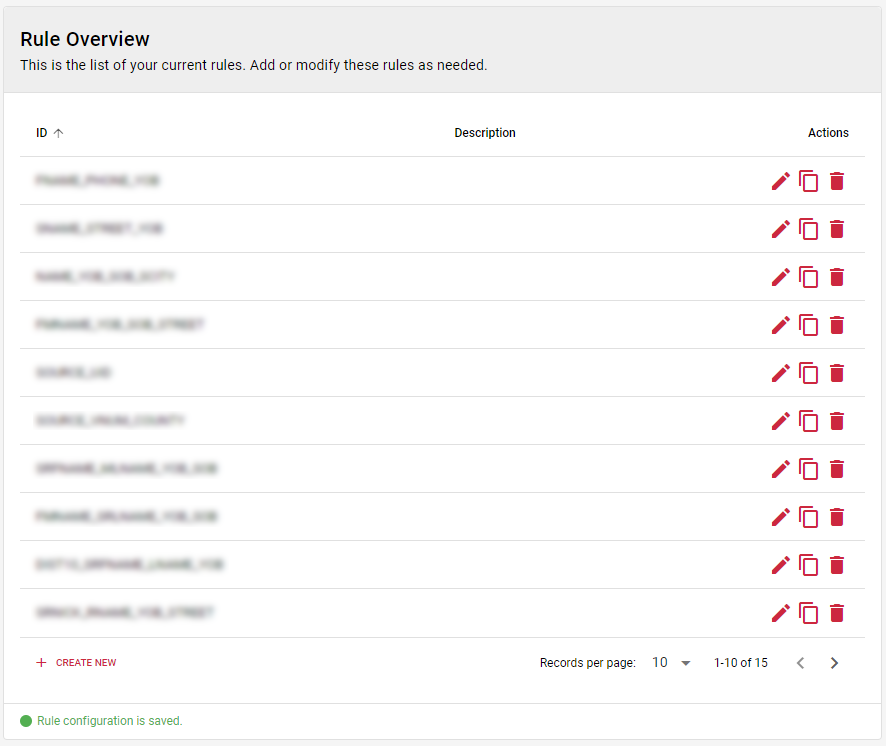
Rule sets bundle multiple rules for a specific use, e.g. for the search. For a
rule set to be satisfied at least one of its rules must be satisfied.
Technically speaking they are OR connected.
By default there is exactly one rule set that is used for both searching and linking.
#
Example: Customize Configuration
Let's create a custom rules configuration. For this example we are going to work with the following simplified schema. In reality the schema is most likely more complex.
input RecordInput {
id: ID!
name: String!
address: String!
}
type Record {
id: ID!
name: String!
address: String!
}
input SearchParams {
name: String!
address: String!
}The rule that we want to create is very simple: match if the names are phonetically similar and the normalized addresses are identical.
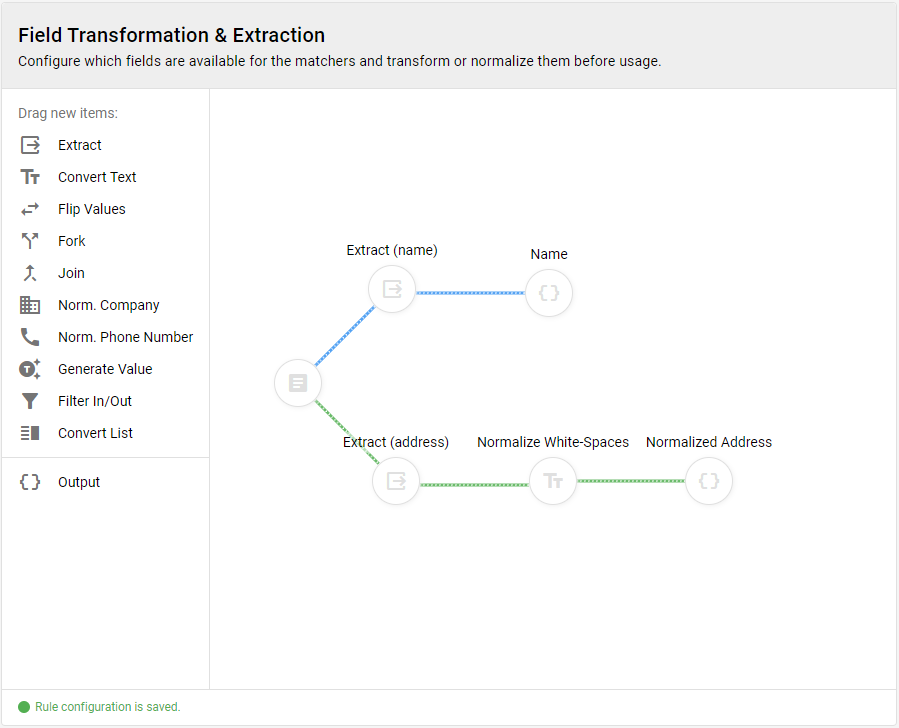
As a first step, we need to create the values used later by the matchers. This is done by creating the appropriate steps in the transformations.
We will create the following transformations:
- Extract Transformation
- Path: name
- Case Sensitive: disabled
- Must Exist: enabled

- Output
- Label: Name

- Extract Transformation
- Path: address
- Case Sensitive: disabled
- Must Exist: enabled


- Output
- Label: Normalized Address

Once you created those transformations, connect them like that:
Next let's setup the tokenization. We will use this for the name matcher later. Create a new tokenizer:
- Type: Word-Based Tokenization

Also for the name matcher, we will need to setup a text comparison. Create a new text comparison:
- Type: Phonetic Similarity
- Algorithm: Metaphone

Now, let's create the reusable matchers.
Start with the simple one for the address:
- Type: Simple Text Equality
- Transformation Output: Normalized Address

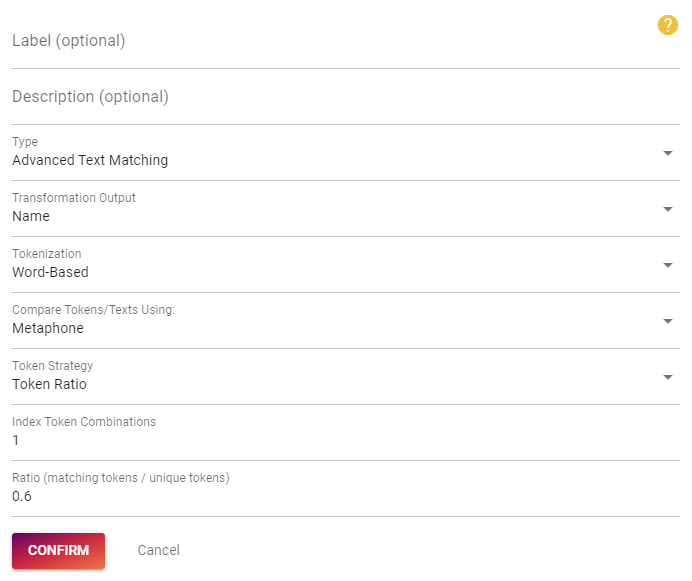
And the name matcher:
- Type: Advances Text Matching
- Transformation Output: Name
- Tokenization: Word-Based
- Compare Tokens/Texts Using: Metaphone
- Token Strategy: Token Ratio
- Index Token Combinations: 1
- Ratio: 0.6
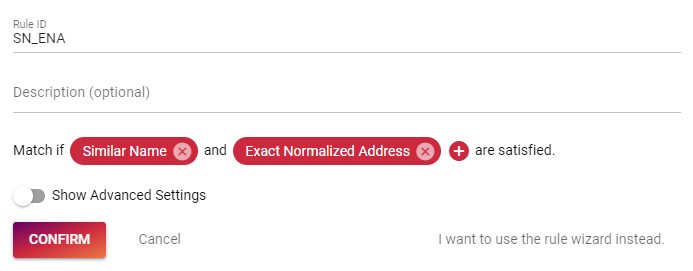
Now combine both matchers into a single rule. Create a new rule:
- Rule ID: SN_ENA (choose what ever you like, but keep it short and concise)
- Match if "Similar Name" and "Exact Normalized Address" are satisfied.
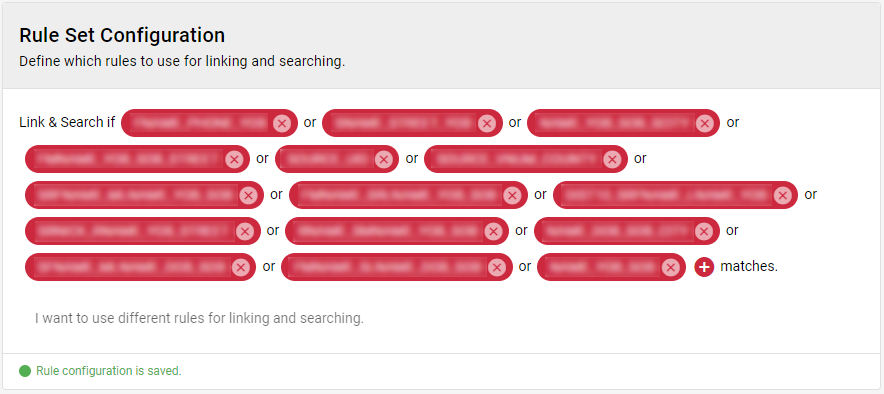
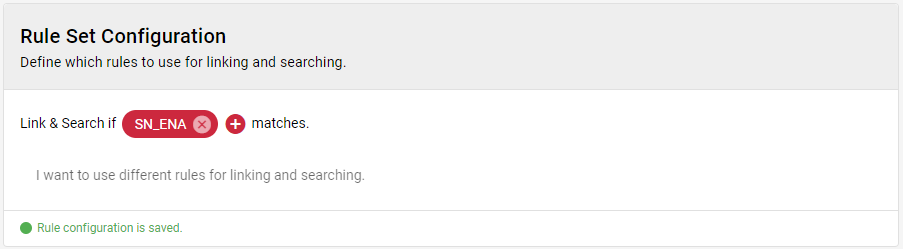
Finally add the new rule to the rule set configuration:
- Link & Search if "SN_ENA" matches.
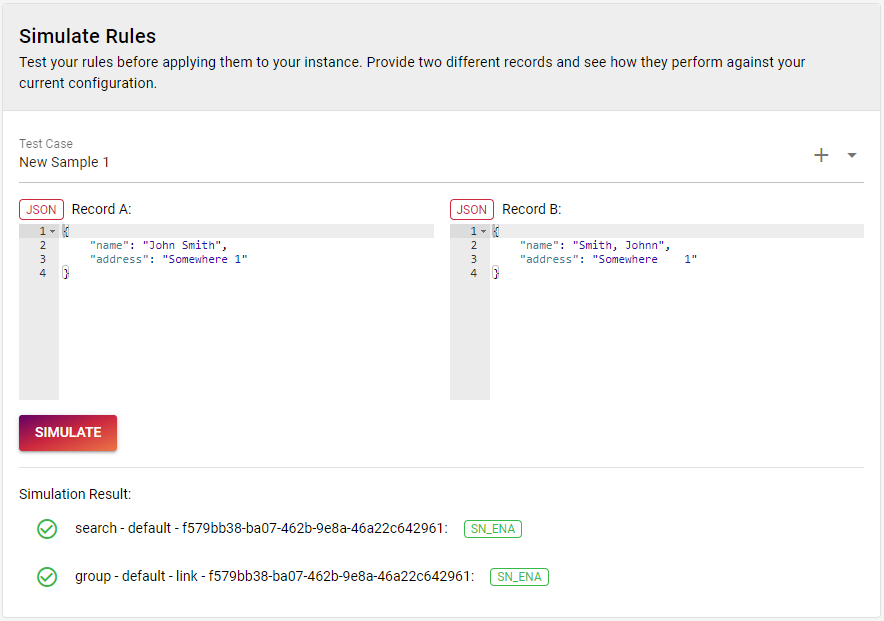
Once done, you can verify that everything works by simulating using the following data:
{
"name": "John Smith",
"address": "Somewhere 1"
}{
"name": "Smith, Johnn",
"address": "Somewhere 1"
}If everything works fine, you should see that the created rule is green in the simulation result output.