#
Consistency
The consistency feature is new and might not work in every case. We're happy to help with configuration and ensuring stability for your use case.
Often you want to improve your matchers via IDs that you have available in your system. For a person use case these might be things like social security number, passport number, driver's license number or customer id.
While for some of those, e.g. the customer id, it is fine (often even expected) that a single entity contains multiple of these IDs, others indicate an obvious wrong match (e.g. social security number).
Tilores allows you to configure rules for matching on ID values and to guarantee uniqueness within a single entity. The following example walks you through the steps that are required to setup such a rule.
#
Step 1: Understand Your Data
Before you can setup rules you should understand your data:
- Which fields are available?
- For which fields do you need entity consistency?
- What does your schema look like?
For ID fields we typically see one of the following four possible scenarios when it comes to the schema:
- a single ID value, stored in a single field, no specific ID type
- separate fields for different ID values, field name defines the ID type
- a single field with a map where the ID type is the maps key and the value is the ID
- a single field with an array of nested objects and specific attributes indicating the ID and its type such as (
valueandtype)
For the purpose of this example, we assume that the data is following the last case previously described.
The data for a single record might look something like this (simplified):
{
"id": "record-id",
"name": "John Smith",
"commonIDs": [
{"type": "SSN", "value": "1234567890"},
{"type": "DriveLicense", "value": "ABCDEFG"}
]
}The data schema for the RecordInput would therefore look like this:
input RecordInput {
id: ID!
name: String!
commonIDs: [CommonIDInput!]!
}
input CommonIDInput {
type: String!
value: String!
}
#
Step 2: Extract the Values
Based on the previously defined schema, we want to match on the name and ensure consistency among the IDs.
For this we need to retrieve the name as well as the ID fields in the "Extract / Transform" page as follows:
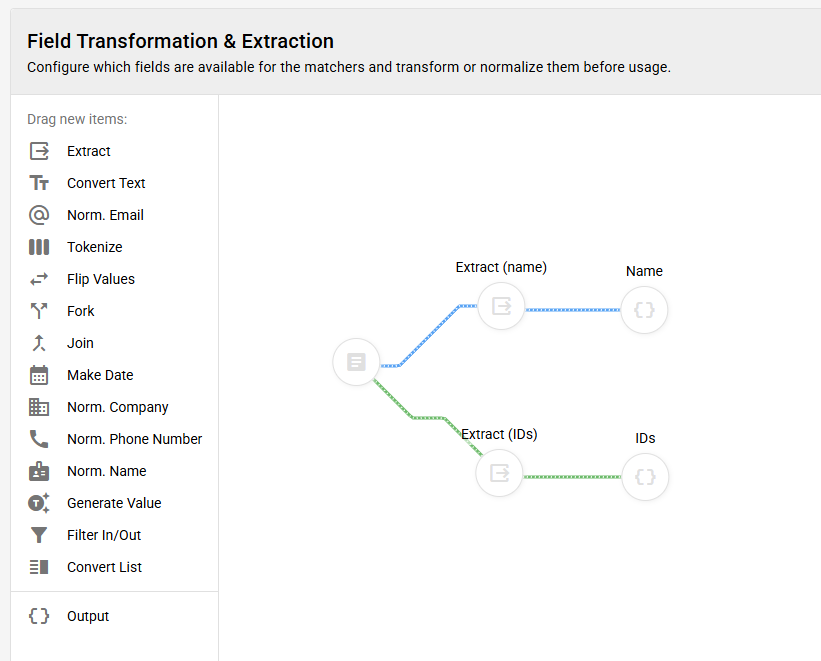
The output for the IDs must either be a map or an array of arrays. Either of the two following formats is fine:
{
"ssn": "1234567890",
"type": "abcdefg"
}[
["ssn", "1234567980"],
["type", "abcdefg"]
]Since we're already working with array based data, we will transform into the
array version using a simple jq-like pattern ([.commonIDs[] | [.type, .value]])
right in the extract step:

You can use the simulation right below the transformation configuration to ensure that the final output is correct. Simply paste the record example into "Record A" and press simulate. Afterwards hover over each output to see the result.
#
Step 3: Setup Matching Rule
To ensure matching for equal names, we can setup a simple text matcher using the name output that we just created.
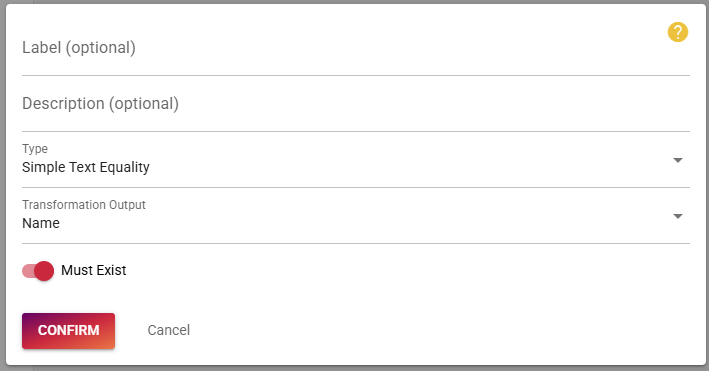
Afterwards create the matching rule and ensure that it has been added to the rule set for linking and searching.
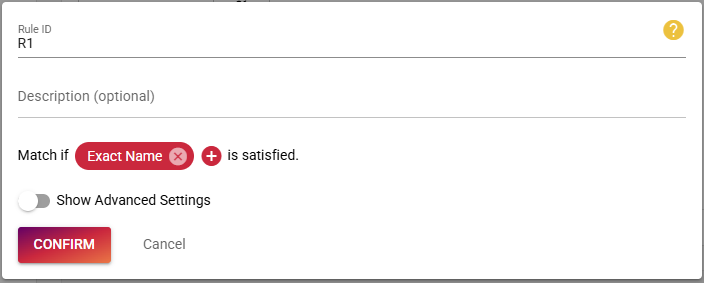
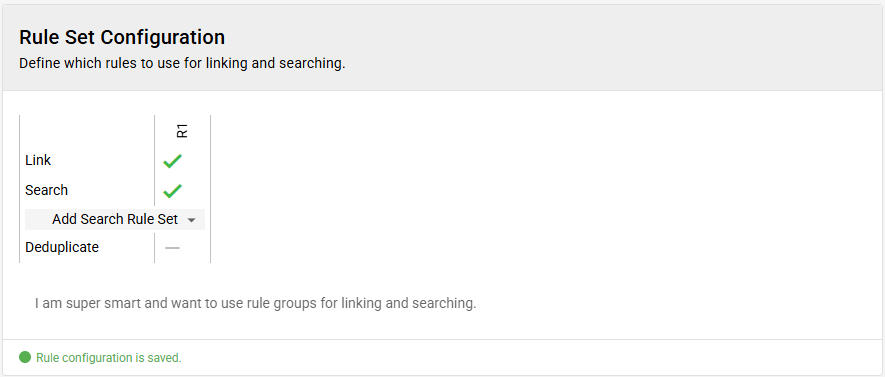
If your rule set configuration looks differently, you can click on the text that says: "I want to use different rules for linking and searching."
#
Step 4: Setup Consistency Rule
With this rule in place, every record with the name "John Smith" would now be added to the same entity ID. To ensure, that there is an ID consistency within a single entity, we need to setup the according rule.
We start by creating a matcher that allows us to match IDs.
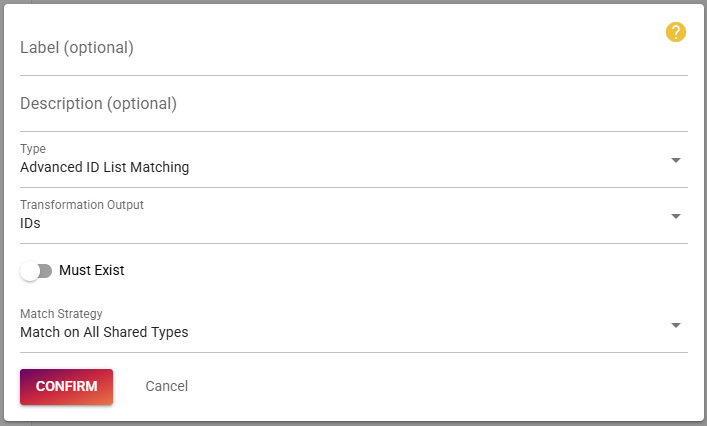
Please ensure, that you selected the "Match on All Shared Types" strategy and that you disabled the "Must Exist" option. Disabling this option allows two records without an ID to match and is a requirement for the next step.
If one record does have an ID while another record does not have any IDs at all, we still want to consider this as a consistent match. To allow this we need to additionally configure an "Empty Aware" matcher. Notice how it wraps the matcher that we just created.
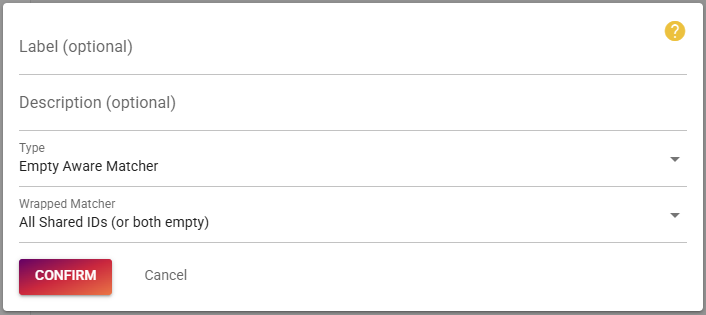
The next step is to setup the consistency rule:
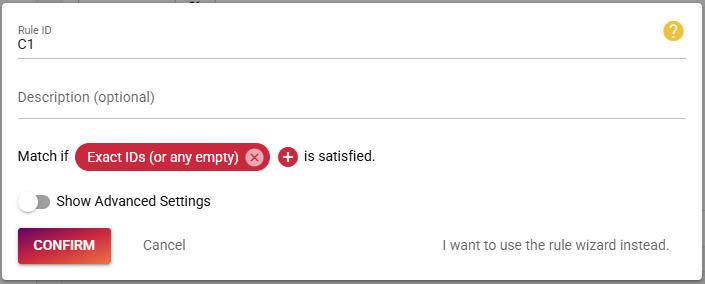
and to enable the consistency rule set with that newly created rule:
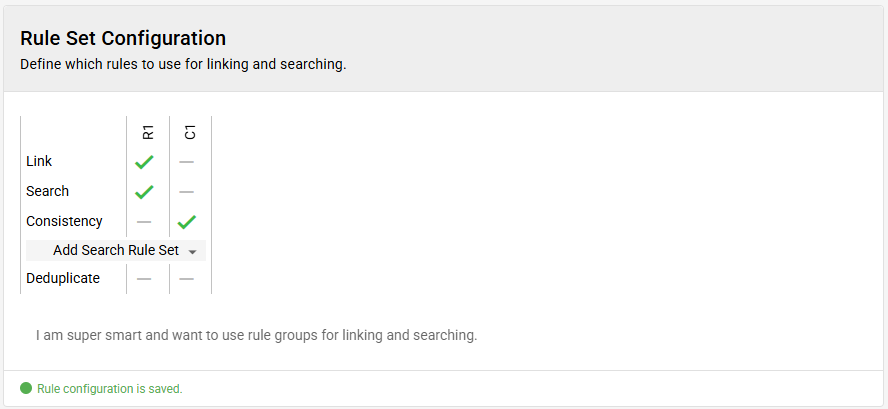
There is no consistency rule set available by default. You can add one by clicking on the small arrow next to "Add Search Rule Set" and then select "Add Consistency Rule Set".
#
Performance Considerations
With the steps performed, you would properly separate entities with diverging IDs. However, this comes at some costs and should be used sparsely to guarantee consistency. Internally a new record will find all those entities as potential matches. Then Tilores will compare the new record against all existing records of the potential target entities. While this is optimized internally, this still might lead to a lot of comparisons needed in some situations (e.g. many distinct entities or entities with huge number of records).
#
Consistency vs Matching Rules
If you're now wondering why we are not simply using matching rules instead of consistency rules, please have a look at the following three records:
{
"id": "a",
"name": "John Smith",
"commonIDs": [
{"type": "SSN", "value": "1234567890"}
]
}{
"id": "b",
"name": "John Smith",
"commonIDs": []
}{
"id": "c",
"name": "John Smith",
"commonIDs": [
{"type": "SSN", "value": "0987654321"}
]
}Matching rules in Tilores are always comparing record pairs and if a match exists between any two records, those records will end up in the same entity.
In the above example a will match with b and b will match with c. Hence,
all three records will end up in the same entity.
Consistency rules work by checking the new record against all records of the potential target entity. If a single record will not match with the new record then the whole entity is not considered a potential match.
When providing a record that matches with two inconsistent entities, consistency rules ensure that those two entities are not merged. The new record will instead be assigned to the older of the two entities or in the unlikely event of exact timestamps, to the larger entity. If the entities are the same age and size, the record is assigned randomly to one of them.