#
Public SaaS Walkthrough
Outdated
This guide is not yet up to date. We have made changes to the UI and currently have no easy way of importing the rule configuration.
To test Tilores with realworld data, we provide an example configuration and also generated test data.
#
Use Case
In this example we want to ingest person data (name, address, …) into Tilores and link the ingested records to entities. So that for each person only one entity exists, no matter how many records were ingested for that person.
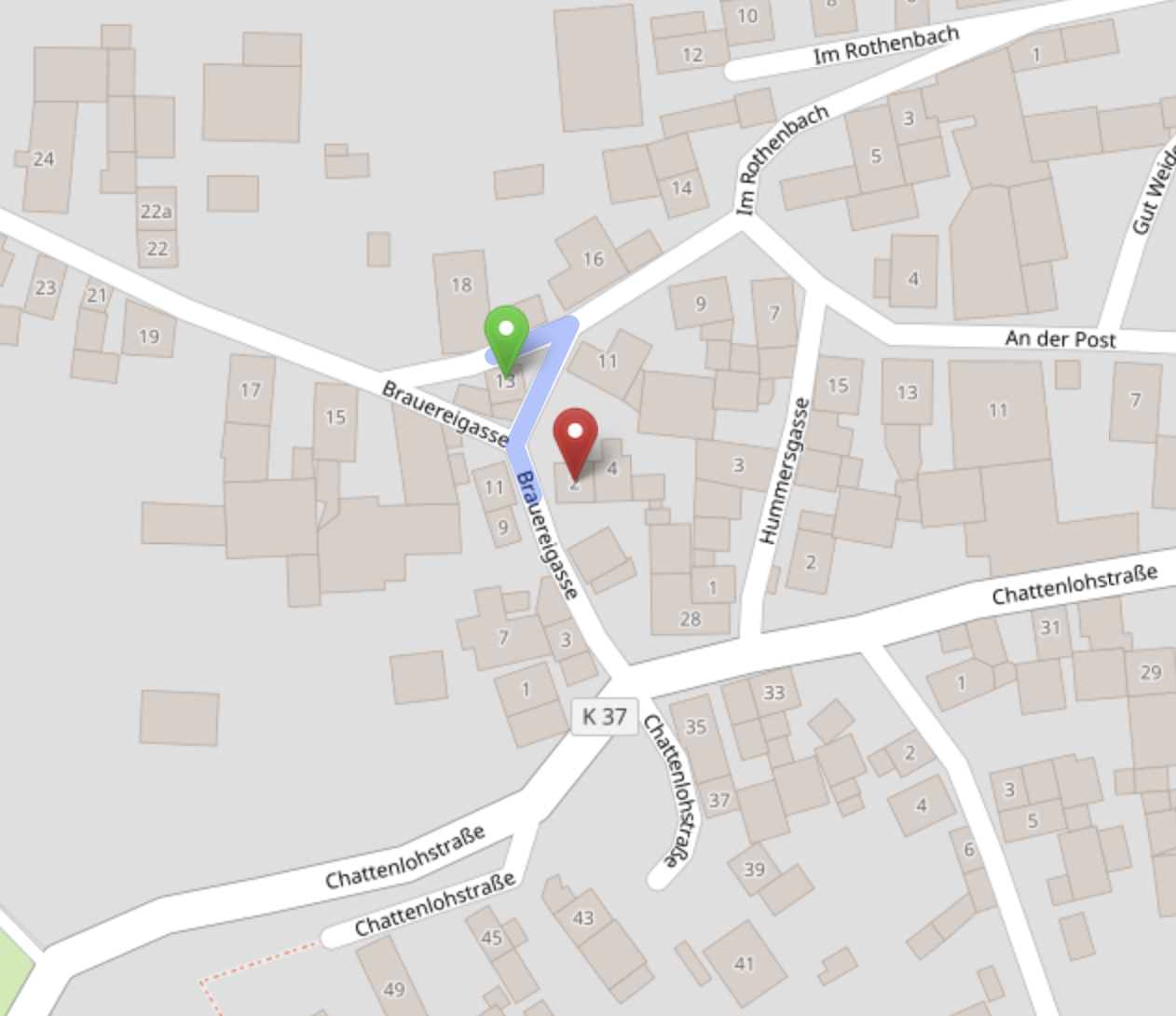
Imagine you have these two records of the same person:
As the first name is not exactly the same and also the address and the geo coordinates are different, a normal database would not be able to match both records to one person (entity).
We will now start to configure Tilores, so that it matches both records.
#
Prerequisites
Please sign up for a new account at app.tilores.io. After sign in, deploy your first Tilores instance. For this just enter a name for the instance and click deploy. When this is done we can start with the configuration of the schema. For that please delete the current JSON in Tilores - Manage Instance - Data Schema screen and replace it with this JSON. Click SAVE.
input RecordInput {
"""Id provides a unique identifier for this record."""
id: ID!
entityID: String
firstName: String
lastName: String
birthName: String
dateOfBirth: String
dateOfDeath: String
gender: String
street: String
houseNumber: String
houseNumberSupplement: String
postalCode: String
city: String
district: String
country: String
latitude: Float
longitude: Float
source: String
}
type Record {
"""Id provides a unique identifier for this record."""
id: ID!
entityID: String
firstName: String
lastName: String
birthName: String
dateOfBirth: String
dateOfDeath: String
gender: String
street: String
houseNumber: String
houseNumberSupplement: String
postalCode: String
city: String
district: String
latitude: Float
longitude: Float
source: String
}
input SearchParams {
id: ID
firstName: String
lastName: String
birthName: String
dateOfBirth: String
dateOfDeath: String
gender: String
street: String
houseNumber: String
houseNumberSupplement: String
postalCode: String
city: String
district: String
country: String
latitude: Float
longitude: Float
}Please click SAVE before continuing.
The advanced steps for a schema configuration are explained in our schema documentation. In simple words, we define the inputs, outputs and search parameters for Tilores in this configuration.
#
Inputs
It starts with the inputs at input RecordInput. Here we define the record. A record represents a single data point of your entity and is the most important data structure to store any kind of information in. The first attribute is the id which is the only mandatory attribute you always have to use.
You see that it is mandatory as it ends with an exclamation mark. If you also want other attributes to be mandatory when ingesting records, add an exclamation mark at the end of the line.
The
idfor each record has to be unique. If you add the same record with the sameidtwo times, the second one is discarded.
Now all the other attributes that are needed to store details of a person are defined. As you can see, none of the attributes is mandatory. So you could only ingest an address or a name. Which attributes should be mandatory depend on your use case.
#
Outputs
Next the outputs are defined starting at type Record. Often inputs and outputs are the same but if needed for your use case, both can be different. For our example, both are the same.
As the inputs and outputs are defined, we now have to define the search parameters.
#
Search
Often the search parameters are just a subset of the outputs, but they can also be the same. Also note, that in order to use the fields defined in the search parameters they must be used in the search rules configuration. A more detailed description of the search parameters can be found in our documentation.
The schema is now defined and we can move on to create rules to match the records.
#
Rules
Please navigate to Tilores - Manage Instance - Matching Rules and replace the JSON with this one and click SAVE.
{
"comparers": [
{
"id": "comparer-cologne",
"type": "phonetic",
"attributes": {
"algorithm": "cologne"
}
},
{
"id": "comparer-dynamic-cologne-levenshtein",
"type": "dynamicdistance",
"attributes": {
"comparerID": "comparer-cologne",
"distanceAlg": "levenshtein",
"distanceRanges": [
{
"minLength": 0,
"allowedDistance": 0
},
{
"minLength": 4,
"allowedDistance": 1
},
{
"minLength": 7,
"allowedDistance": 2
},
{
"minLength": 10,
"allowedDistance": 3
}
]
}
}
],
"tokenizers": [
{
"id": "tokenizer-word",
"type": "word"
}
],
"transformers": [
{
"id": "field-firstname",
"type": "field",
"attributes": {
"path": "firstName",
"caseSensitive": false,
"mustExist": true,
"outputPins": [
"default"
]
},
"inputPins": {
"default": null
}
},
{
"id": "field-lastname",
"type": "field",
"attributes": {
"path": "lastName",
"caseSensitive": false,
"mustExist": true,
"outputPins": [
"default",
"for-name-birthname"
]
},
"inputPins": {
"default": null
}
},
{
"id": "field-birthname-or-empty",
"type": "field",
"attributes": {
"path": "birthName",
"caseSensitive": false,
"mustExist": false,
"outputPins": [
"default",
"for-name-birthname"
]
},
"inputPins": {
"default": null
}
},
{
"id": "field-city",
"type": "field",
"attributes": {
"path": "city",
"caseSensitive": false,
"mustExist": true,
"outputPins": [
"default"
]
},
"inputPins": {
"default": null
}
},
{
"id": "field-postalcode",
"type": "field",
"attributes": {
"path": "postalCode",
"caseSensitive": false,
"mustExist": true,
"outputPins": [
"default",
"for-substr3"
]
},
"inputPins": {
"default": null
}
},
{
"id": "field-street",
"type": "field",
"attributes": {
"path": "street",
"caseSensitive": false,
"mustExist": true,
"outputPins": [
"default"
]
},
"inputPins": {
"default": null
}
},
{
"id": "field-housenumber",
"type": "field",
"attributes": {
"path": "houseNumber",
"caseSensitive": false,
"mustExist": true,
"outputPins": [
"default"
]
},
"inputPins": {
"default": null
}
},
{
"id": "field-dob",
"type": "field",
"attributes": {
"path": "dateOfBirth",
"caseSensitive": false,
"mustExist": true,
"outputPins": [
"default"
]
},
"inputPins": {
"default": null
}
},
{
"id": "field-dob-or-empty",
"type": "field",
"attributes": {
"path": "dateOfBirth",
"caseSensitive": false,
"mustExist": false,
"outputPins": [
"default"
]
},
"inputPins": {
"default": null
}
},
{
"id": "field-lat",
"type": "field",
"attributes": {
"path": "latitude",
"caseSensitive": false,
"mustExist": true,
"outputPins": [
"default"
]
},
"inputPins": {
"default": null
}
},
{
"id": "field-lng",
"type": "field",
"attributes": {
"path": "longitude",
"caseSensitive": false,
"mustExist": true,
"outputPins": [
"default"
]
},
"inputPins": {
"default": null
}
},
{
"id": "field-id",
"type": "field",
"attributes": {
"path": "id",
"caseSensitive": false,
"mustExist": true,
"outputPins": [
"default"
]
},
"inputPins": {
"default": null
}
},
{
"id": "transformer-substring",
"type": "stringop",
"attributes": {
"operation": "substring",
"inputPins": [
"postalCode"
],
"length": 3
},
"inputPins": {
"postalCode": {
"sourceID": "field-postalcode",
"sourcePin": "for-substr3"
}
}
},
{
"id": "transformer-join-lastname-birthname",
"type": "join",
"attributes": {
"outputPins": [
"name-birthname"
],
"inputsPerOutput": 2,
"strategy": "stringConcat",
"separator": " "
},
"inputPins": {
"name-birthname0": {
"sourceID": "field-lastname",
"sourcePin": "for-name-birthname"
},
"name-birthname1": {
"sourceID": "field-birthname-or-empty",
"sourcePin": "for-name-birthname"
}
}
}
],
"resolvers": [
{
"id": "resolver-firstname",
"inputPin": {
"sourceID": "field-firstname",
"sourcePin": "default"
}
},
{
"id": "resolver-lastname",
"inputPin": {
"sourceID": "field-lastname",
"sourcePin": "default"
}
},
{
"id": "resolver-city",
"inputPin": {
"sourceID": "field-city",
"sourcePin": "default"
}
},
{
"id": "resolver-postalcode",
"inputPin": {
"sourceID": "field-postalcode",
"sourcePin": "default"
}
},
{
"id": "resolver-postalcode3",
"inputPin": {
"sourceID": "transformer-substring",
"sourcePin": "postalCode"
}
},
{
"id": "resolver-street",
"inputPin": {
"sourceID": "field-street",
"sourcePin": "default"
}
},
{
"id": "resolver-housenumber",
"inputPin": {
"sourceID": "field-housenumber",
"sourcePin": "default"
}
},
{
"id": "resolver-dob",
"inputPin": {
"sourceID": "field-dob",
"sourcePin": "default"
}
},
{
"id": "resolver-lat",
"inputPin": {
"sourceID": "field-lat",
"sourcePin": "default"
}
},
{
"id": "resolver-lng",
"inputPin": {
"sourceID": "field-lng",
"sourcePin": "default"
}
},
{
"id": "resolver-lastname-birthname",
"inputPin": {
"sourceID": "transformer-join-lastname-birthname",
"sourcePin": "name-birthname"
}
},
{
"id": "resolver-id",
"inputPin": {
"sourceID": "field-id",
"sourcePin": "default"
}
},
{
"id": "resolver-dob-or-empty",
"inputPin": {
"sourceID": "field-dob-or-empty",
"sourcePin": "default"
}
},
{
"id": "resolver-birthname-or-empty",
"inputPin": {
"sourceID": "field-birthname-or-empty",
"sourcePin": "default"
}
}
],
"matchers": [
{
"id": "matcher-firstname-exact",
"type": "simple",
"attributes": {
"resolverID": "resolver-firstname"
}
},
{
"id": "matcher-firstname-token",
"type": "token",
"attributes": {
"resolverID": "resolver-firstname",
"strategy": "ratio",
"tokenizerID": "tokenizer-word",
"comparerID": "comparer-dynamic-cologne-levenshtein",
"ratio": 0.5
}
},
{
"id": "matcher-lastname-exact",
"type": "simple",
"attributes": {
"resolverID": "resolver-lastname"
}
},
{
"id": "matcher-lastname-token",
"type": "token",
"attributes": {
"resolverID": "resolver-lastname",
"strategy": "ratio",
"tokenizerID": "tokenizer-word",
"comparerID": "comparer-dynamic-cologne-levenshtein",
"ratio": 0.5
}
},
{
"id": "matcher-city-exact",
"type": "simple",
"attributes": {
"resolverID": "resolver-city"
}
},
{
"id": "matcher-postalcode-exact",
"type": "simple",
"attributes": {
"resolverID": "resolver-postalcode"
}
},
{
"id": "matcher-postalcode3",
"type": "simple",
"attributes": {
"resolverID": "resolver-postalcode3"
}
},
{
"id": "matcher-street-exact",
"type": "simple",
"attributes": {
"resolverID": "resolver-street"
}
},
{
"id": "matcher-housenumber-exact",
"type": "simple",
"attributes": {
"resolverID": "resolver-housenumber"
}
},
{
"id": "matcher-dob-exact",
"type": "simple",
"attributes": {
"resolverID": "resolver-dob"
}
},
{
"id": "matcher-lat-lng",
"type": "geodistance",
"attributes": {
"latResolverID": "resolver-lat",
"lngResolverID": "resolver-lng",
"distance": 5.0,
"initialDistance": 5.0
}
},
{
"id": "matcher-lastname-birthname-token",
"type": "token",
"attributes": {
"resolverID": "resolver-lastname-birthname",
"strategy": "overlap",
"tokenizerID": "tokenizer-word",
"comparerID": "comparer-dynamic-cologne-levenshtein",
"maxAdditionalTokens": 2,
"maxProcessableTokens": 4,
"mode": "includesAllOther",
"removeDuplicateTokens": false
}
},
{
"id": "matcher-id-exact",
"type": "simple",
"attributes": {
"resolverID": "resolver-id"
}
},
{
"id": "matcher-dob-or-empty",
"type": "simple",
"attributes": {
"resolverID": "resolver-dob-or-empty"
}
},
{
"id": "matcher-birthname-or-empty",
"type": "simple",
"attributes": {
"resolverID": "resolver-birthname-or-empty"
}
}
],
"rules": [
{
"id": "P1_NEBA",
"matcherIDs": [
"matcher-firstname-exact",
"matcher-lastname-exact",
"matcher-city-exact",
"matcher-postalcode-exact",
"matcher-street-exact",
"matcher-housenumber-exact",
"matcher-dob-exact"
],
"attributes": {
"ignoreErrors": true
}
},
{
"id": "P2_NEA",
"matcherIDs": [
"matcher-firstname-exact",
"matcher-lastname-exact",
"matcher-city-exact",
"matcher-postalcode-exact",
"matcher-street-exact",
"matcher-housenumber-exact"
],
"attributes": {
"ignoreErrors": true
}
},
{
"id": "P3_NPBA",
"matcherIDs": [
"matcher-firstname-token",
"matcher-lastname-token",
"matcher-city-exact",
"matcher-postalcode-exact",
"matcher-street-exact",
"matcher-housenumber-exact",
"matcher-dob-exact"
],
"attributes": {
"ignoreErrors": true
}
},
{
"id": "P4_NPA",
"matcherIDs": [
"matcher-firstname-token",
"matcher-lastname-token",
"matcher-city-exact",
"matcher-postalcode-exact",
"matcher-street-exact",
"matcher-housenumber-exact"
],
"attributes": {
"ignoreErrors": true
}
},
{
"id": "P5_NPBG",
"matcherIDs": [
"matcher-firstname-token",
"matcher-lastname-token",
"matcher-dob-exact",
"matcher-lat-lng"
],
"attributes": {
"ignoreErrors": true
}
},
{
"id": "P6_NPBP3",
"matcherIDs": [
"matcher-firstname-token",
"matcher-lastname-token",
"matcher-postalcode3",
"matcher-dob-exact"
],
"attributes": {
"ignoreErrors": true
}
},
{
"id": "P7_FNELNOBA",
"matcherIDs": [
"matcher-lastname-birthname-token",
"matcher-firstname-exact",
"matcher-city-exact",
"matcher-postalcode-exact",
"matcher-street-exact",
"matcher-housenumber-exact",
"matcher-dob-exact"
],
"attributes": {
"ignoreErrors": true
}
},
{
"id": "P8_ID",
"matcherIDs": [
"matcher-id-exact"
],
"attributes": {
"ignoreErrors": true
}
},
{
"id": "D1_NEBXA",
"matcherIDs": [
"matcher-firstname-exact",
"matcher-lastname-exact",
"matcher-city-exact",
"matcher-postalcode-exact",
"matcher-street-exact",
"matcher-housenumber-exact",
"matcher-dob-or-empty",
"matcher-birthname-or-empty"
],
"attributes": {
"ignoreErrors": true
}
}
],
"ruleSets": [
{
"id": "ruleset-index",
"ruleIDs": [
"P1_NEBA",
"P2_NEA",
"P3_NPBA",
"P4_NPA",
"P5_NPBG",
"P6_NPBP3",
"P7_FNELNOBA",
"P8_ID",
"D1_NEBXA"
]
},
{
"id": "ruleset-link",
"ruleIDs": [
"P1_NEBA",
"P2_NEA",
"P3_NPBA",
"P4_NPA",
"P5_NPBG",
"P6_NPBP3",
"P7_FNELNOBA"
]
},
{
"id": "ruleset-search",
"ruleIDs": [
"P1_NEBA",
"P2_NEA",
"P3_NPBA",
"P4_NPA",
"P5_NPBG",
"P6_NPBP3",
"P7_FNELNOBA",
"P8_ID"
]
},
{
"id": "ruleset-deduplicate",
"ruleIDs": [
"D1_NEBXA"
]
}
],
"searchRuleSetIDs": {
"default": "ruleset-search"
},
"mutationRuleSetGroups": {
"default": {
"indexRuleSetID": "ruleset-index",
"linkRuleSetID": "ruleset-link",
"deduplicateRuleSetID": "ruleset-deduplicate"
}
}
}You can read the in depth explanation of the rules and all details in our rules documentation.
#
Rule Definition
For our example we start at the top of the JSON. First the rules are defined. A rule is a combination of different criteria that need to be met to be true. Our first rule P1_NEBA demands that the first name, last name, address and birthdate match exactly. This is done by using matchers. A rule can have one or more matchers. For a rule to match, all matchers need to match. So all matchers within a rule are AND connected. You might wonder why we use three different matchers - complete, fieldEquality and exact - just for the same thing - to check if attributes match. For the first rule we really could use only the fieldequality matcher and get the same result. However to show you how matchers are connected, we used three different matchers here.
The second rule P2_NEA is similar to the first one, but does not compare the birthdate. So it is less strict than P1_NEBA.
With the third rule P3_NPBA we start with more interesting matching, where attributes are not exactly the same. The first matcher in P3_NPBA compares tokens of an attribute and then does a phonetic comparison based on an phonetic algorithm. Additionally also the address and the birthdate have to be exactly the same.
If we take the first name from our example above, you see that Mariana and Mariana Da are not exactly the same. To match both we can’t just compare both fields, but have to use the token matcher to be able to compare each token. So we compare
the first token of the first record Mariana with the first token of the second record Mariana and the second token of the first record with the second token of the second record Da. As our ratio in P3_NPBA is 0.5 and 1 of two tokens is matching, this matcher is satisfied.
On top of the tokens, we also use phonetics to match. This means that the tokens do not need to be exactly the same but need to sound similar. For that we take the last name of our example record Akoumou and for the second record add an u at the end - Akoumouu. As both names sound similar, the phonetics library matches both.
Instead of the dynamicCologneLevenshtein algorithm also others like soundex or metaphone can be used. This really depends on the data.
P4_NPA is similar to P3_NPBA but it does not compare the birthdate, so it is less strict and also works if a birthdate is not provided.
P5_NPBG is the first rule that is able to match the example use case, where the name is not exactly the same and the address is completely different. It starts with the matchers that we used in rule P3_NPBA - token and phonetics for the name and exact date of birth. The third matcher in P5_NPBG is the geoDistance matcher.
This advanced matcher takes geo coordinates as input and calculates the distance between both. In our case, we define a maximum distance for the matcher to be satisfied of five kilometers. The distance between the addresses/coordinates of both records is 0.32 kilometers. That means that this rule is satisfied and both records would be matched by rule P5_NPBG.
One very important thing to mention is that you should not only rely on an address or radius to match two records to one entity. However you can use this for the search like search for all entities within this radius.
P6_NPBP3 tries also to match records when the address is not the same and no coordinates are available. For that it uses the first 3 digits of the zipcode. To do this, the exact matcher is used with the substr3 modifier. Modifiers are used to manipulate strings and the matchers then compare based on that manipulated string.
As for the geoDistance matcher, also the zipcode should be used with other matchers so that we do not end up with false positives.
P7_FNELNOBA needs an exact match for the first name, for the birthdate and address, however it combines the birthname and the last name for matching and uses the tokenOverlap matcher.
This is used when the last name has several tokens like
lastname: Akoumou
lastname: Akoumou
birthname: MüllerThe overlap matcher matches both as equal as one token in each record matches - Akoumou. For finetuning of this matcher, please check the documentation. As the token overlap matcher can be quite loose, it is important to use it in combination with other more strict rules like in this case the exact first name and the exact birthdate. Otherwise you would match records of different persons to one entity.
P8_ID is a special rule compared to the other ones before. It is used so that we can search for the ID of a record to find the whole entity. It is only used for indexing and searching but not for matching. In our schema, the ID is unique - so only one record with the same ID can exist in our instance.
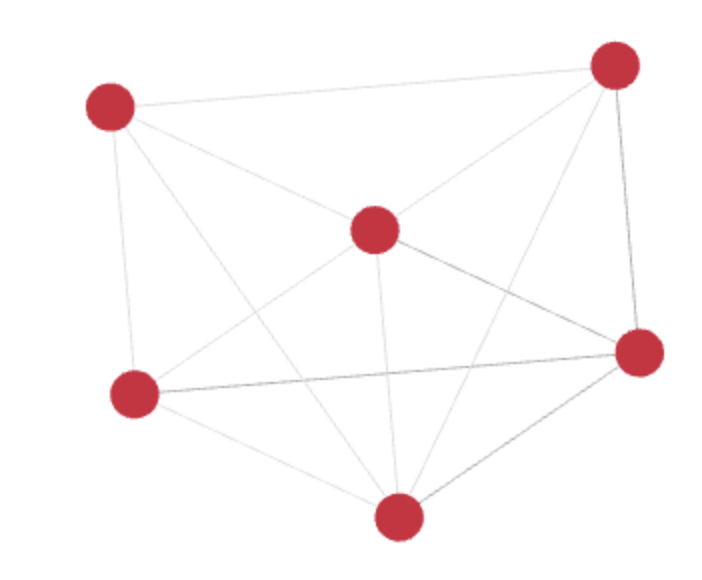
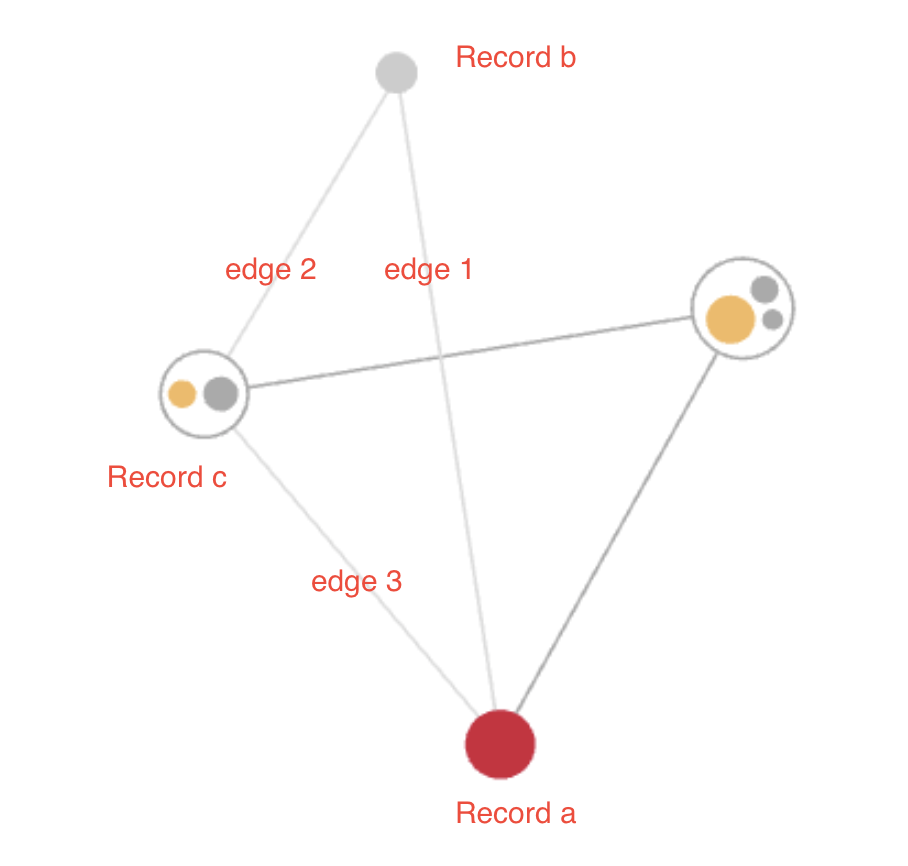
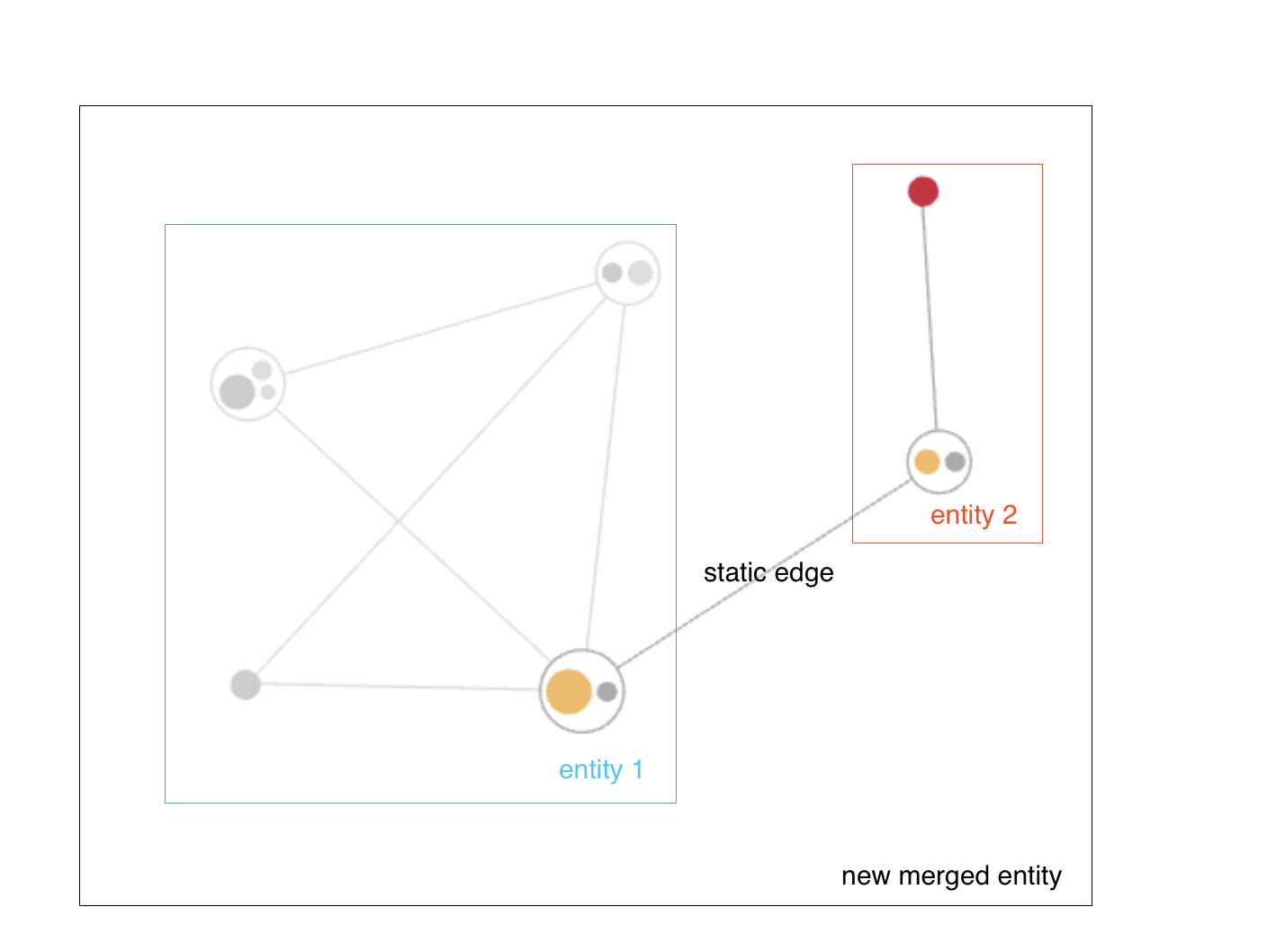
D1_NEBXA is the last rule and also has a special meaning. It is a deduplication rule that is used to deduplicate non identical duplicate records. In this rule records are matched as duplicates if the first and last name are exactly the same and the data of birth and birth name are either exactly the same or empty. Other attributes like gender, district or country can be different. This is used so that no links are created between records, that are only different in not matching relevant attributes as otherwise a huge mesh with many edges would be created like in this graphic:
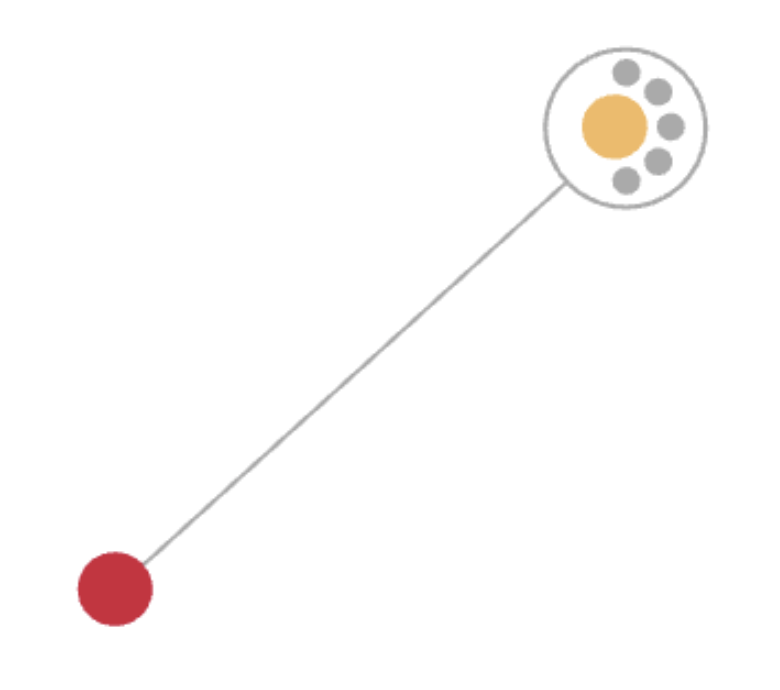
Using the deduplication rule the entity it looks like this:

The yellow dot is the master record and the grey dots are the duplicates. If other records are added to the entity, then only one connection would be created to the master record but not to the other duplicate records. So in this example instead of 12 edges between the records we only have one edge.
#
Rulesets
Now the rules are created, but we did not define how the rules are connected so that from two records an entity is created. This is done in the rulesets section. For each use case you can define a ruleset. Normally this is done for searching, matching and deduplication.
The rules are OR connected which means that at least one rule of a ruleset needs to be satisfied so that two records that are compared will get linked.
The searchRuleSet can only include one ruleset for searching, the mutationRuleSetGroups contains all rules used for indexing, deduplication and matching.
Our current configuration is not deployed to our instance yet. We will explain how this can be done later.
#
Simulate Rules
To activate rule changes, you need to redeploy your instance. That takes 5 minutes and if you are trying to fine tune your rules it might not make sense to redeploy for each minor adjustment to see if it works out. This is why we created the rules simulator. It takes the schema and rule configuration and then compares two records if they match using your current rules. For that the rules do not need to be deployed, so you can change your rules, simulate the outcome, change it again… until you are happy with the matching. The simulator uses the rules in the UI, you do not need to save them for using the rules simulator.
When you are happy with the rules, you click SAVE and then redeploy.
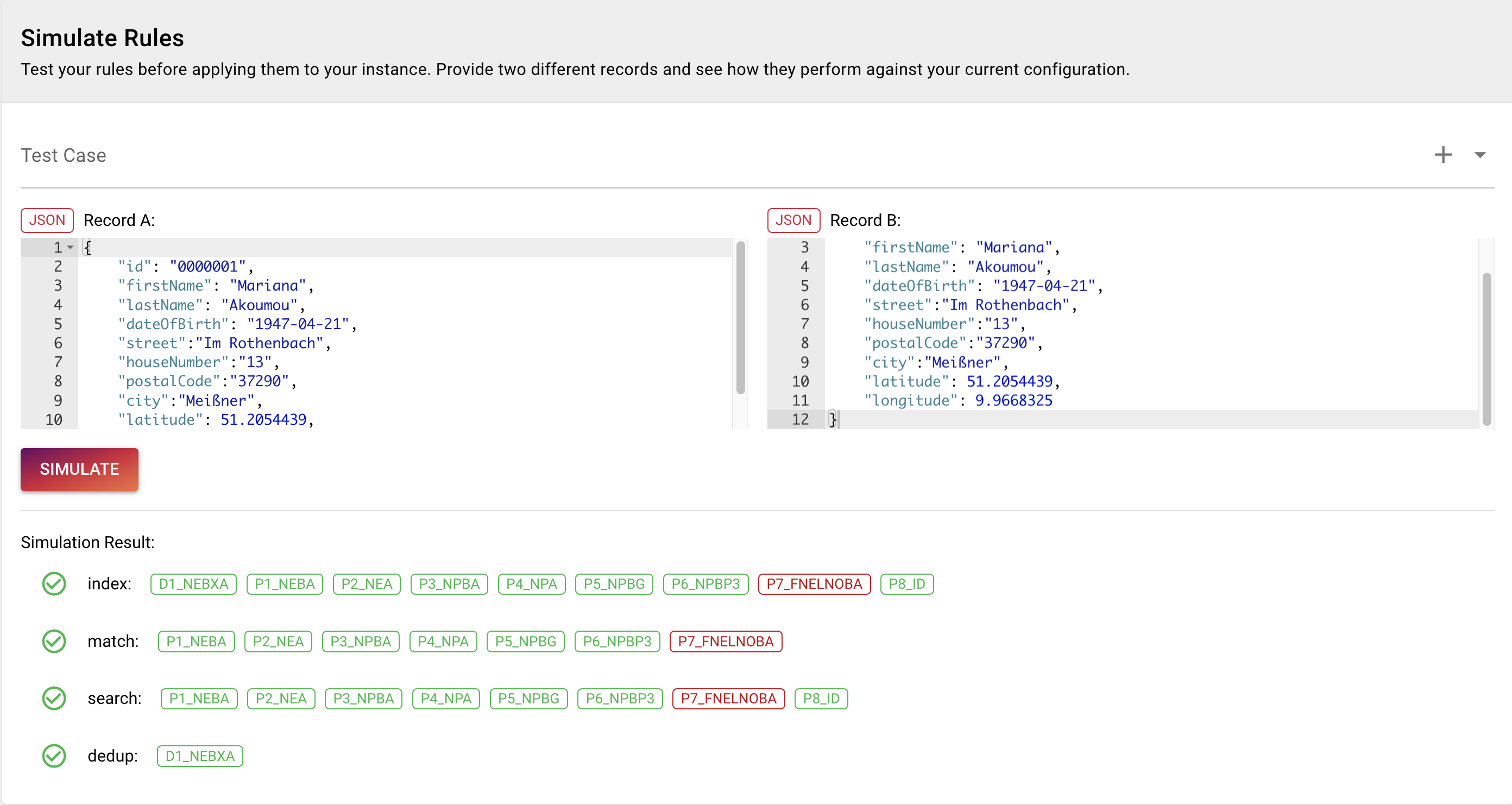
To try out your rules, start with the same data in Record A and Record B. Enter the data and click SIMULATE.
{
"id": "0000001",
"firstName": "Mariana",
"lastName": "Akoumou",
"dateOfBirth": "1947-04-21",
"street":"Im Rothenbach",
"houseNumber":"13",
"postalCode":"37290",
"city":"Meißner",
"latitude": 51.2054439,
"longitude": 9.9668325
}Now you see the different matching rules per ruleset. As our data is exactly the same, all rules except for the overlap rule match.
If we now replace the data in Record B with that
{
"id":"0000002",
"firstName":"Mariana Da",
"lastName":"Akoumou",
"dateOfBirth":"1947-04-21",
"street":"Brauereigasse",
"houseNumber":"2",
"postalCode":"37290",
"city":"Meißner",
"latitude":"51.204261",
"longitude":"9.971033"
}We see that not all rules are matching anymore.
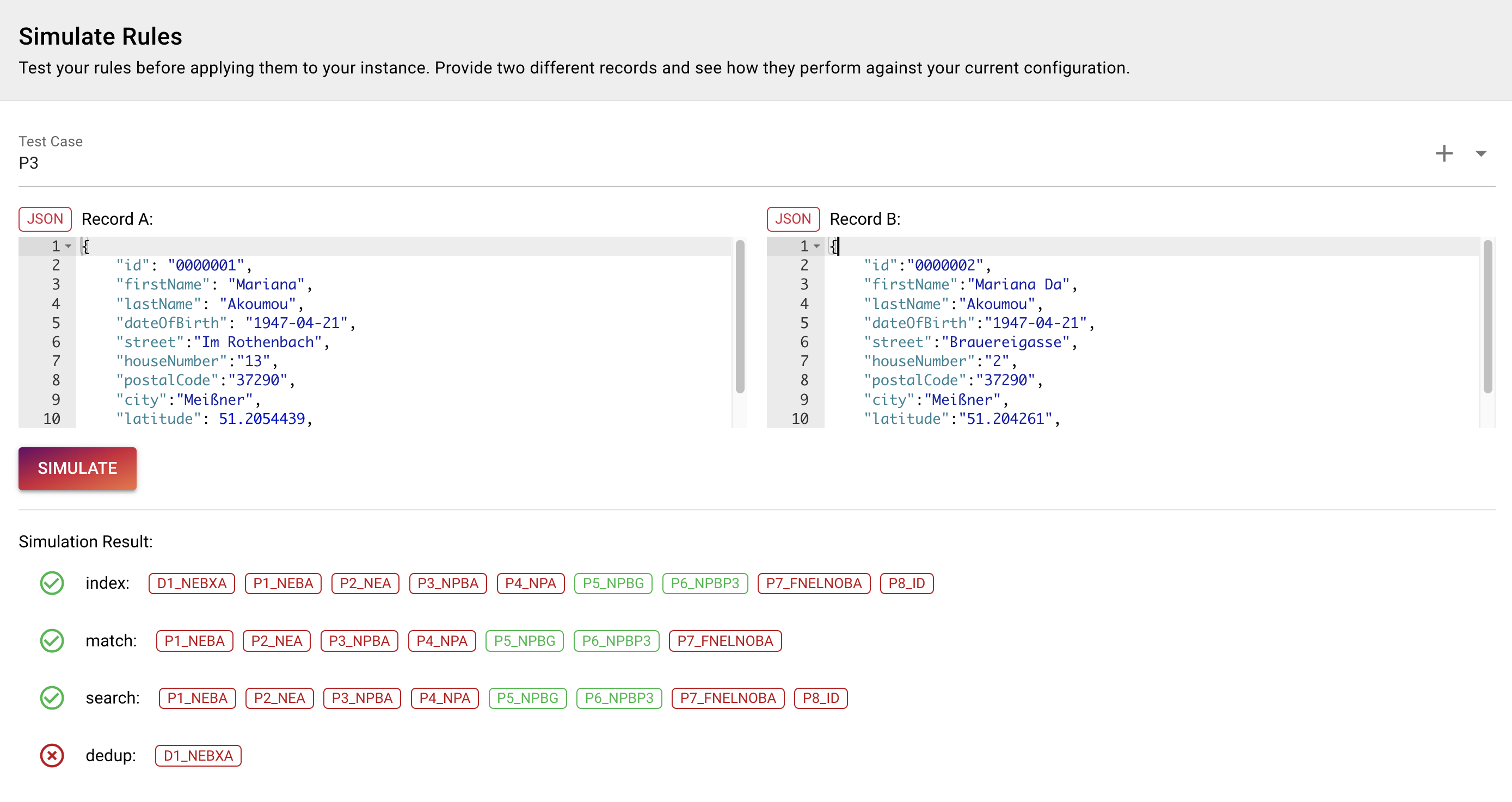
Only P5_NPBG and P6_NPBP3 are matching as the address is not exactly the same anymore but close by. As for now the rules work and we want to deploy our changes.
#
Advanced Settings (Redeploy, Destroy, Delete)
Please navigate to Tilores - Manage Instance - Advanced Settings. In this section, you control the state of your instance.
#
Redeploy
For any changes in your schema or rules and also to use new features that were released after you deployed your instance for the last time, you have to redeploy.
This updates your instance with the latest version of the Tilores software and your configuration. As we are using a serverless system, you do not have any downtime during deployments. This means you can continue to ingest data and you can also search.
To redeploy just click REDEPLOY and the magic starts. If you leave the current page, you can still see the process for the REDEPLOY on top of the navigation.
#
Destroy
If you want to empty your instance you just click DESTROY, confirm it afterwards and all your data is deleted. You might want to use this after testing to then start with a clean instance to insert your production data. DESTROY will keep your schema and rules configuration, so that when you deploy again, the configuration is still there. However, the API credentials are removed.
#
Delete
When you want to completely delete your instance, you first have to use the DESTROY functionality and then press DELETE. This will additionally to deleting all data also remove all configuration. So after pressing DELETE you start from scratch like with a newly created account.
#
Upload data
To upload data there are several ways. In production you usually would use the GraphQL API to upload data. When testing out Tilores it might be easier to use our Ingest Data Screen. Please navigate to Tilores - Ingest Data.
Here you can upload a JSONL (JSON Line) file that uses your schema.
We start with a simple file that contains one line like this:
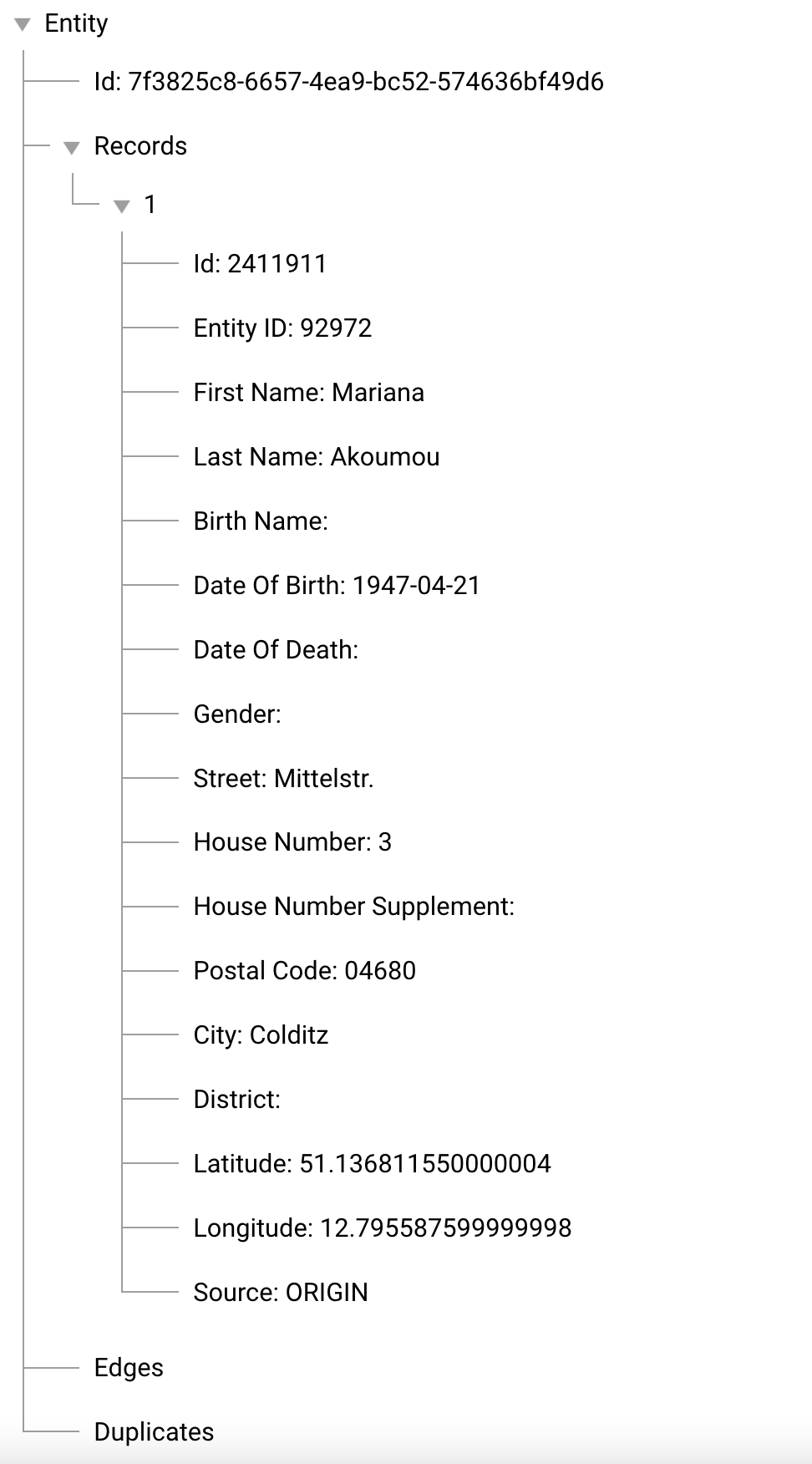
{"entityID":"92972","id":"2411911","source":"ORIGIN","firstName":"Mariana","lastName":"Akoumou","birthName":"","dateOfBirth":"1947-04-21","dateOfDeath":"","gender":"","street":"Mittelstr.","houseNumber":"3","houseNumberSupplement":"","postalCode":"04680","city":"Colditz","district":"","latitude":"51.136811550000004","longitude":"12.795587599999998"}
Download and save this file locally and then drop it into the upload area.
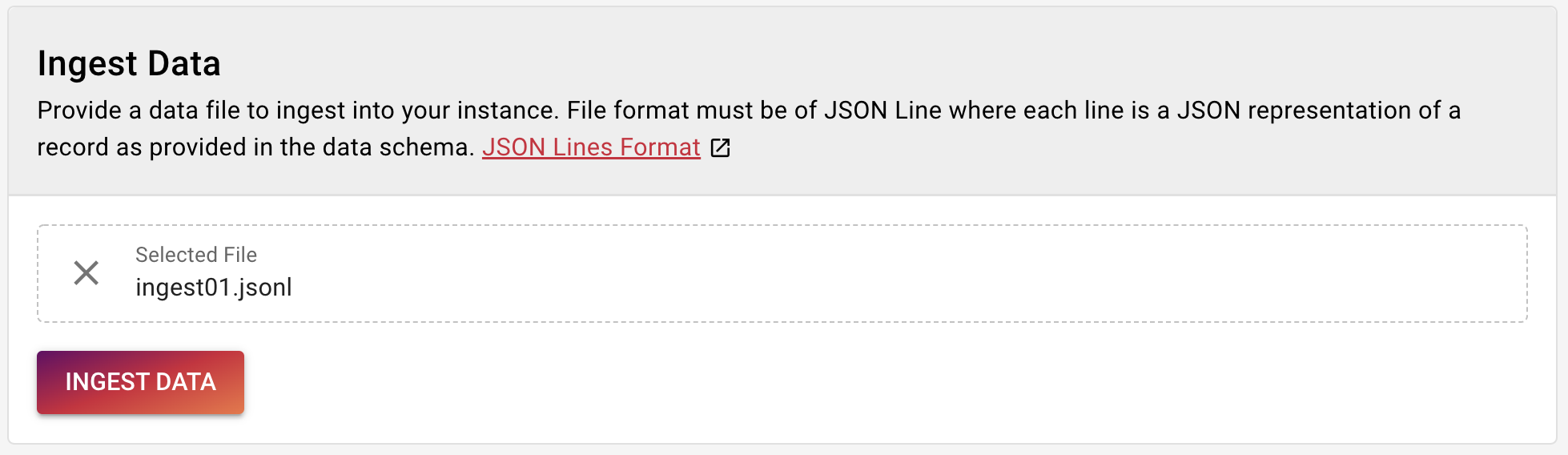
Click Ingest Data and the file is uploaded. Now you should see Records Ingested: 1.
The data was now ingested into the matching process and we can start searching for it. Before we go to the search section, just some side note to the Ingest Data screen. Currently the upload file size is limited to 10 MB and only two records are concurrently uploaded. This is to limit the bandwidth that your browser is using for this. In production you can upload as many parallel streams as you want using the GraphQL API.
#
Search
Now as the first record was ingested we want to see if it is available in our instance. For that
Please navigate to Tilores - Search Entities.
To start simple and only to check if our record was added, we add the id from our file - 2411911 - to the id field and click Search. Now you should see one little dot on your screen. If you click the dot, you will see that data of the record that you ingested before. You can switch to the Data View and now you also see the first information about the newly created entity. This view will be used in later examples to see which records were added to our entity.
#
Further Examples
Now we will upload some more data to see how Tilores works.
First we will upload the same record again, but with a changed id. As the ID has to be unique, a record with the same id would not be ingested but discarded.
After you ingested the file please go back to the Search Entities Screen and search for 2411911. You now see that the ingested record is matched with the first record to one entity. In the Data View we can see that the record with the id 4411911 is a duplicate of the record with the id 2411911. If we expand the tree for records, we will also see all attributes of each record.
You can configure which attributes are shown. For that click the gear icon on the upper right of the screen. Select the attributes that you want to see.

This will only display the first and last name.
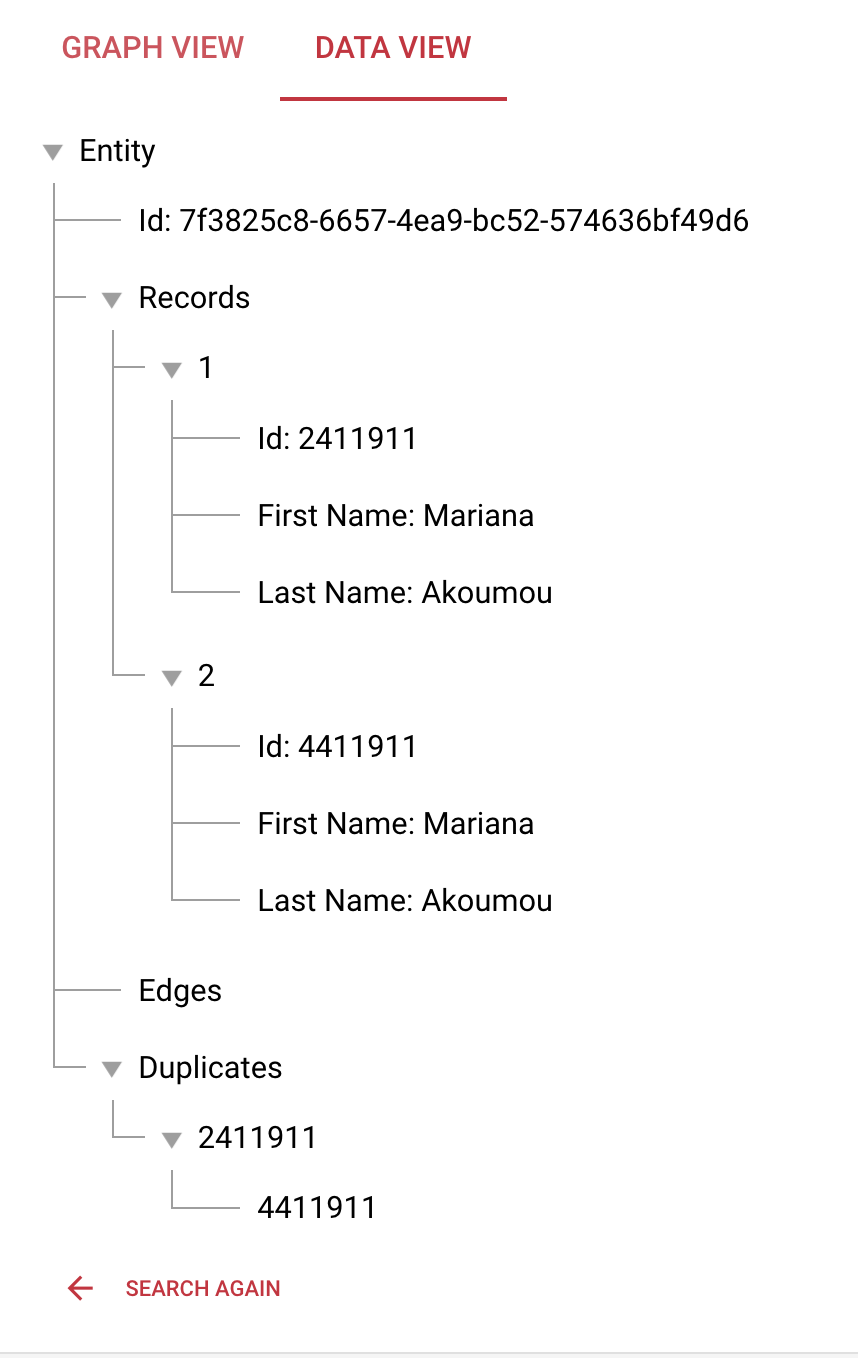
As we can see how duplicates work, we now want to add more data. For that upload the file.
Search again as before and go to the Graph View.
So what is an edge? An edge is the link between two records.
In our case a static edge links two records that were ingested in the same line and that should represent a move of a person from location A to location B.
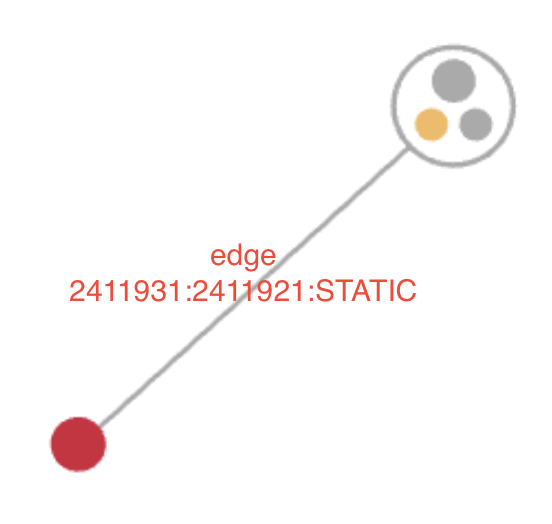
Static edges cannot only be used for a move but also for records that belong to each other but where the rules would not match them.
It is not only possible to connect two records in one line with a static edge but also many. The difference then is, that record A is not only connected to record B and record B to record C. Record C is also connected to record A. So each record that is ingested in the same request or line is statically linked to all other records in that line/request.
Please upload the file.
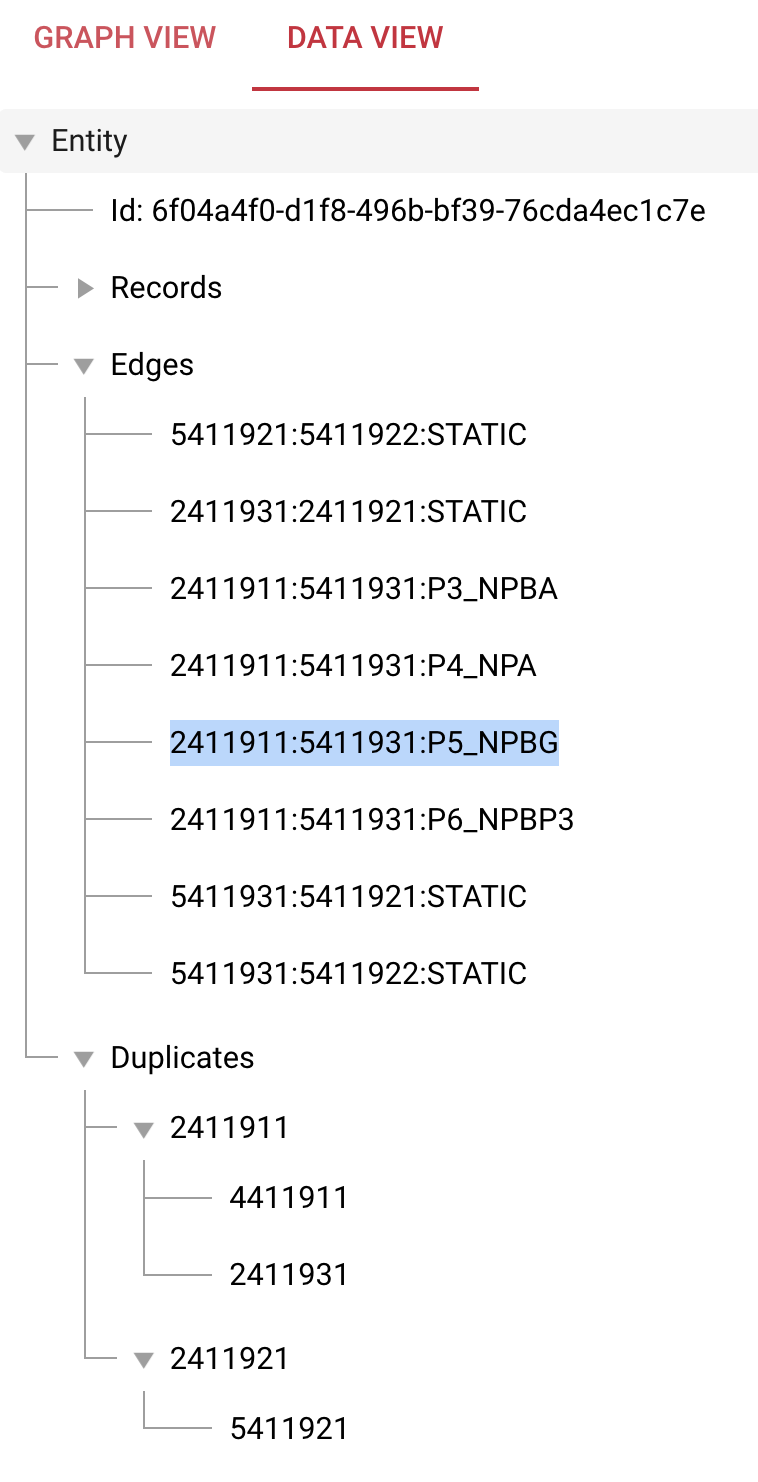
Now the graph should look like this
Please go to the data view. This now shows all information of the records we ingested and that were matched to one entity. We see that we not only have static edges and duplicates but also edges that were created by our rules.
Now we add a record to see how the geomatching works. Please upload the file.
If we search only for ID again, we will not find this record as it does not match with the other records we ingested and searched before using the id. So please use the “Visual Editor” and enter the attributes as shown below.
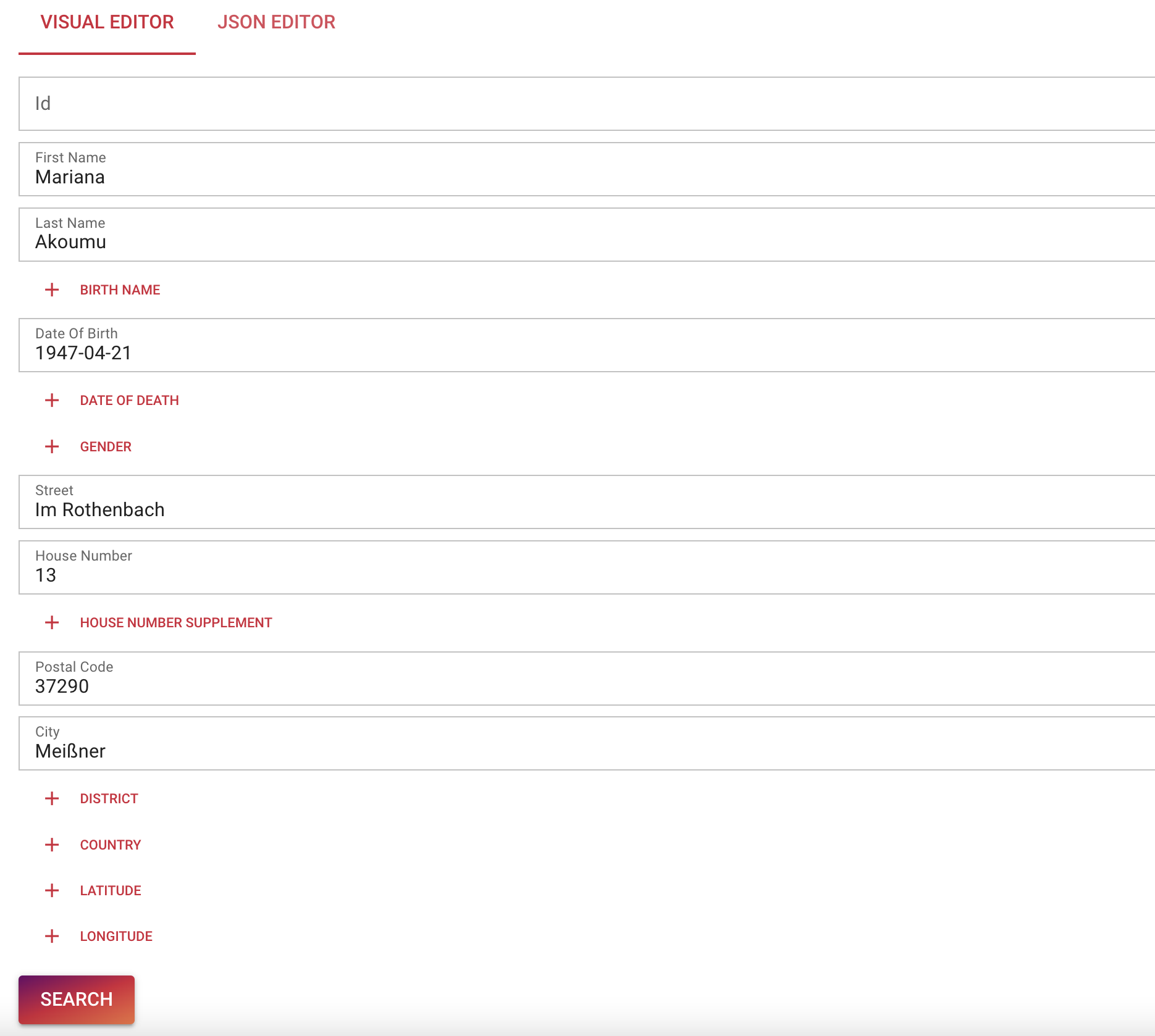
In the “Data View” we can now see, that two records were matched using rules P5 and P6, however these records were not connected to the Mariana Akoumu Entity that we saw before.
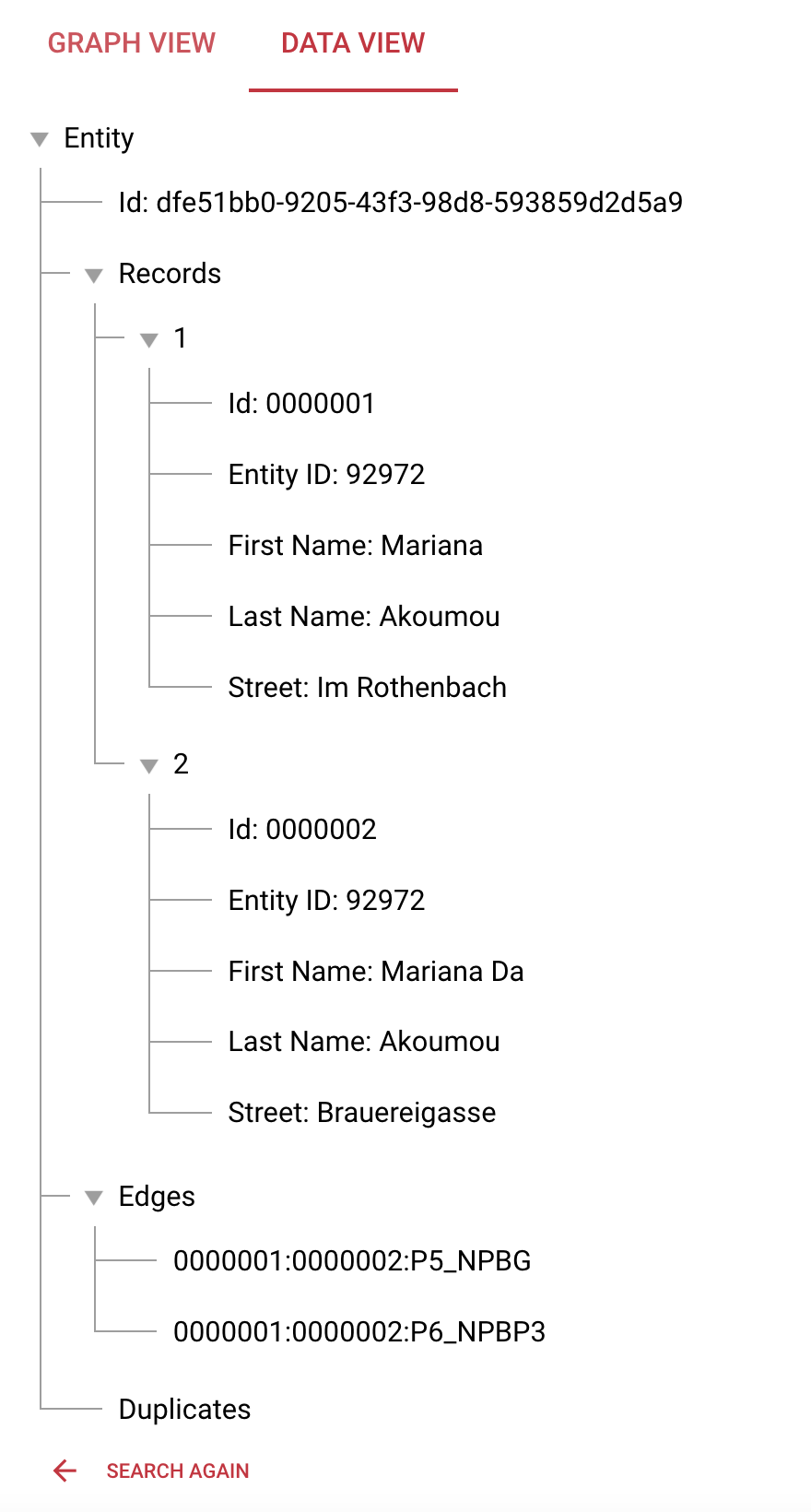
To see both entities, we go back to the Visual Editor and add the id of the record that we used before. Just to mention, if you click JSON Editor, you will see the JSON representation of the search:
{
"id": "2411911",
"firstName": "Mariana",
"lastName": "Akoumu",
"dateOfBirth": "1947-04-21",
"street": "Im Rothenbach",
"houseNumber": "13",
"postalCode": "37290",
"city": "Meißner"
}This you can use the same way as you used the Visual Editor.
Please click search and then navigate to the Data View.

Now you see two pages as this search found two entities. This is the small entity that was just created. It is exactly matched by our first search (without the id). The second entity is exactly matched using the id. So not all search criteria must be met to find entities. As we defined search rules above, one of these rules needs to be satisfied to find an entity.
The big question now is how to connect both entities as we know they belong to each other. The simple answer is that we need to create a link between both entities. This will automatically happen if new data is added that creates this link - like an online shopping event where the billing address is at the location of one of the records from entity 1 and the shipping address is at the location of one of the records from entity 2. If you want to manually connect both entities, you can upload a file with two records, one from the first location and one from the second location.
Please ingest file.
Search for the entity again.
Now you can see that both entities were merged into one entity.
In the Data View you can see the static edge 5411931:0000005:STATIC which is connecting both entities. This merge will change the entity id of the 2nd entity as now there is only one merged entity left. If we would remove the link again, the then newly created 2nd entity would get a new entity id and the other remaining entity will keep its id.
#
Big entities
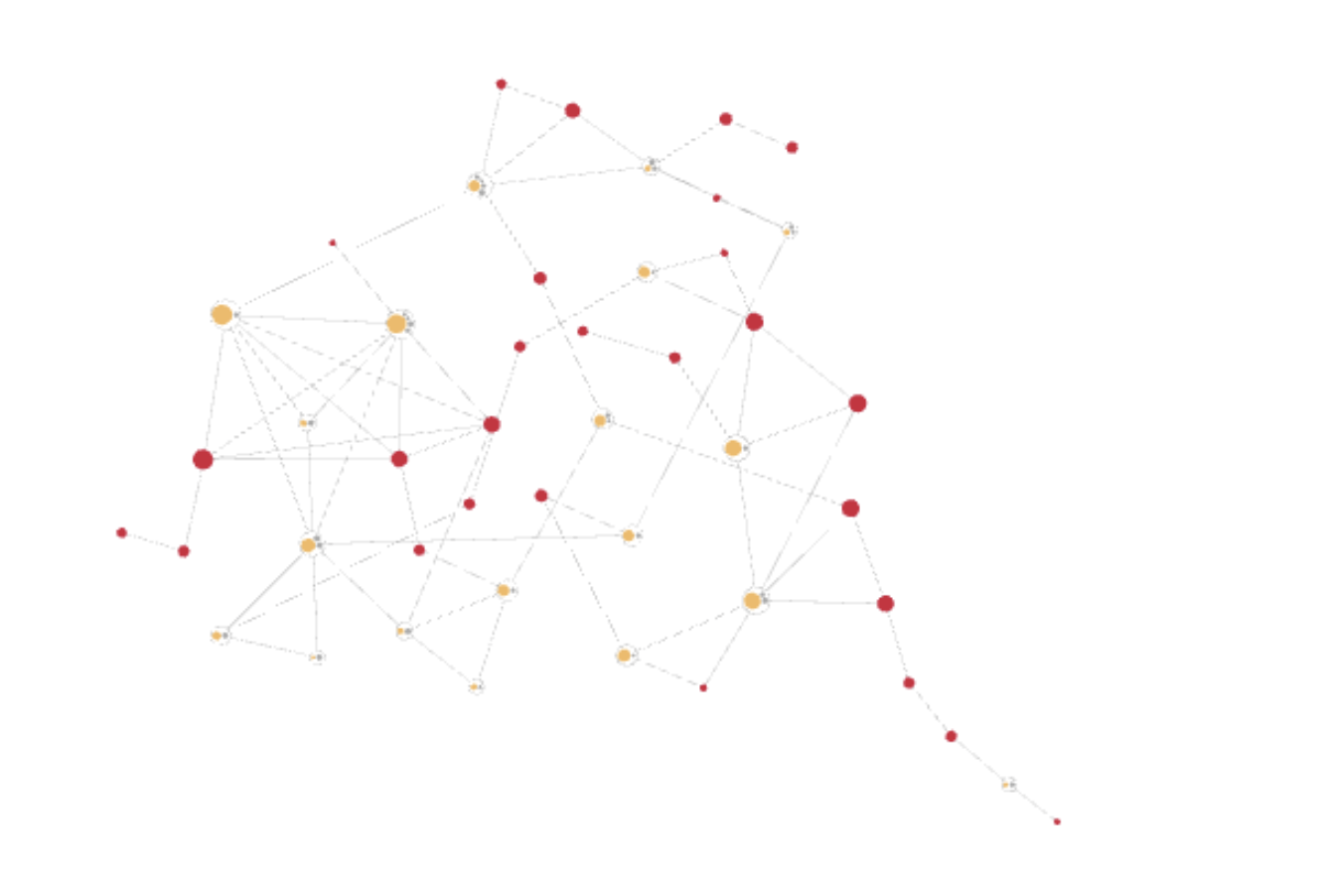
To see what is possible using Tilores, please ingest the last file.
Search again and go to the Graph View. Now you see a much bigger entity than before with many duplicates and edges between the records. As you might have seen, the response time does not increase with more data but is constantly fast.
#
Dashboard
The last page to show in our walkthrough is the dashboard.
Here you can see the details of your instance. First it shows the name, state and creation date on the left. In statistics you can see how many entities and records are stored in your instance. This screen is only updated every 6 hours, so do not wonder if it shows less than you expect.
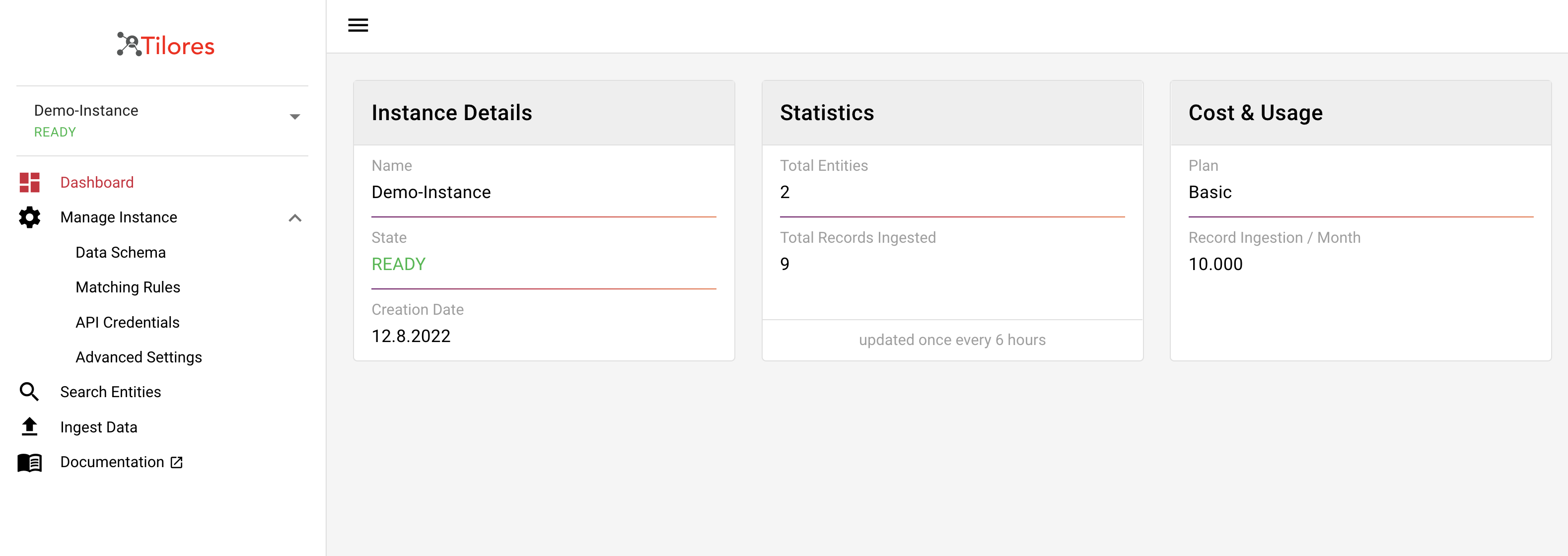
The cost and usage shows you which plan you are using and what the free tier is for that.
Now you can start configuring the instance for your own data and start using it. Please tell us if you have any questions or suggestions via service@tilores.io